Lo esencial para entender por qué un acceso limitado cambia toda la intrusión
- Hablamos de pasar de una cuenta normal a otra con más permisos, como root, SYSTEM o administrador.
- Suele apoyarse en fallos de software, configuraciones débiles, credenciales expuestas o controles de elevación mal diseñados.
- MITRE ATT&CK la trata como una fase distinta dentro de la cadena de ataque, no como un detalle menor.
- En Windows, UAC ayuda a limitar el impacto; en Linux, las capabilities y los permisos marcan gran parte de la superficie de riesgo.
- La defensa más rentable suele ser mínimo privilegio, parcheo, revisión de permisos y auditoría continua de cuentas críticas.
Qué cambia cuando la escalada de privilegios entra en juego
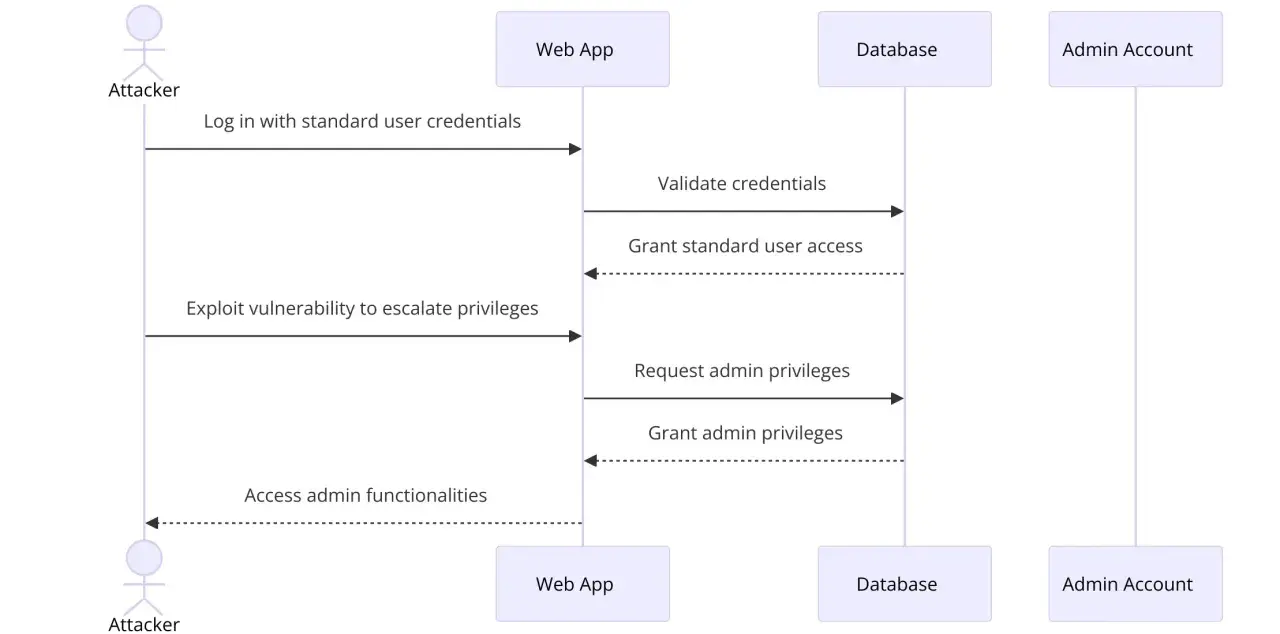
Yo suelo explicar este tema de forma muy simple: una cosa es entrar en un sistema y otra muy distinta es poder hacer cosas que antes estaban bloqueadas. Mientras un atacante está en una cuenta limitada, su margen es pequeño; cuando sube de nivel, puede tocar configuraciones, leer secretos, instalar persistencia o desactivar controles.
MITRE ATT&CK la describe como la fase en la que el adversario busca permisos de nivel superior. Eso encaja con lo que vemos en auditorías reales: muchas intrusiones no empiezan con un fallo “espectacular”, sino con un acceso inicial modesto que luego se convierte en acceso administrativo por exceso de confianza, mala segmentación o permisos mal afinados.
En hacking ético, esta fase importa porque demuestra impacto real. No basta con decir “he entrado”; la pregunta útil es: ¿hasta dónde puedo llegar y qué control tengo realmente? Esa es la frontera entre una prueba superficial y una evaluación que ayuda a priorizar riesgos. Con ese marco, toca mirar las rutas más habituales por las que aparece.
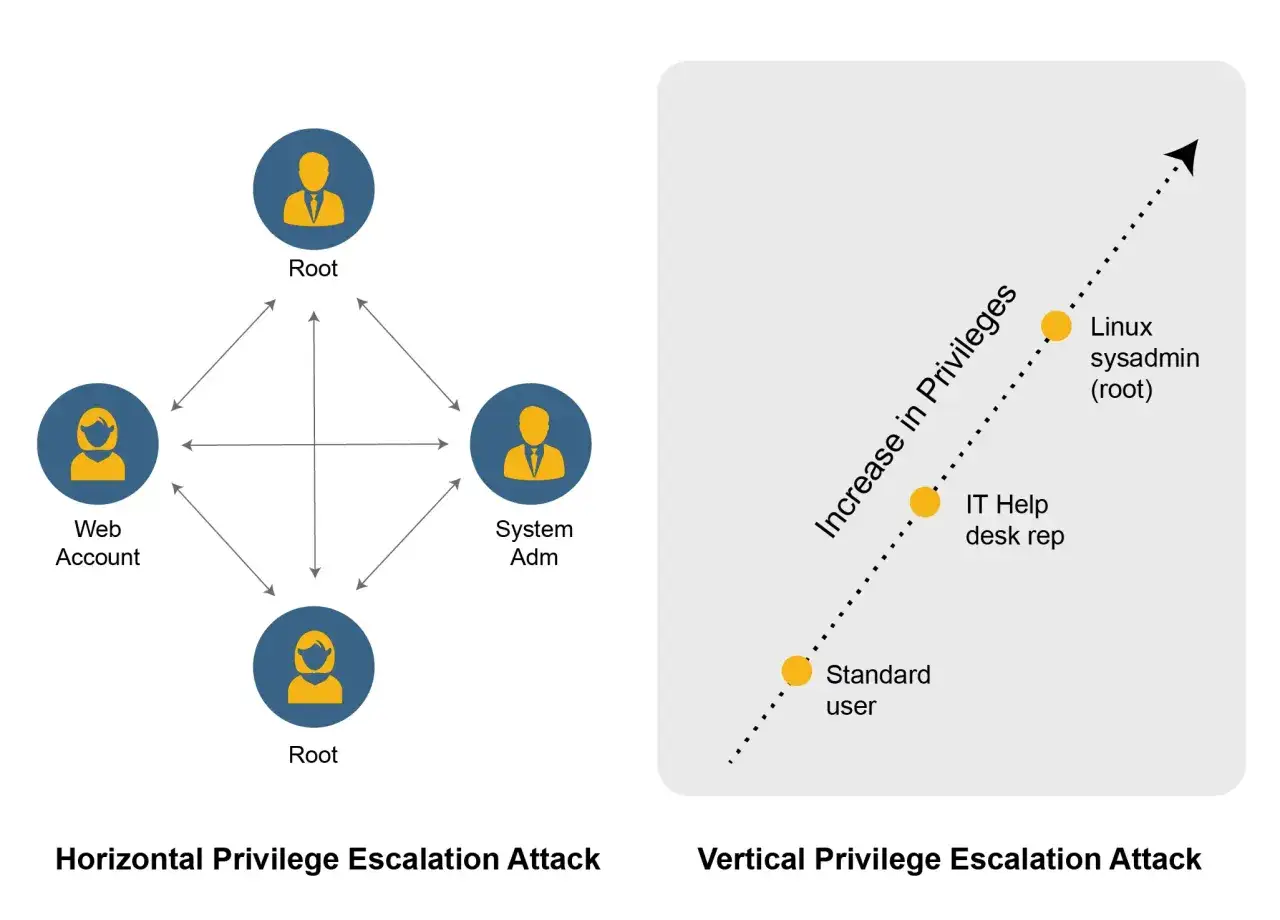
Las rutas más comunes que aprovecha un atacante
No hace falta un exploit exótico para que ocurra. En la práctica, los caminos se repiten bastante y yo los agrupo en cinco familias:
| Ruta | Qué la facilita | Impacto típico | Qué conviene revisar |
|---|---|---|---|
| Vulnerabilidades sin parchear | Software, kernel o servicio con un fallo explotable | Subida a administrador local o root | Inventario, parches, versiones expuestas |
| Permisos excesivos | Usuarios o servicios con más acceso del necesario | Abuso de funciones administrativas | ACL, sudoers, grupos locales, roles IAM |
| Credenciales y tokens expuestos | Contraseñas reutilizadas, secretos en disco o sesión robada | Acceso a cuentas privilegiadas | Vaults, rotación, MFA, secretos en scripts |
| Controles de elevación mal diseñados | UAC, setuid, setgid o capabilities mal configuradas | Ejecución con contexto más potente | Políticas de elevación, binarios heredados, permisos especiales |
| Entornos cloud o contenedores sobrerrepresentados | Roles demasiado amplios o imágenes con privilegios innecesarios | Escalada dentro del clúster o de la cuenta cloud | IAM, permisos de pods, secretos montados, cuentas de servicio |
Mi lectura es bastante clara: el problema rara vez es una sola pieza, sino la combinación de un acceso inicial pequeño más una segunda debilidad administrativa. Por eso las revisiones de permisos y de configuración son tan valiosas como el parcheo. Y una vez entendido dónde suelen aparecer las rutas, la siguiente pregunta lógica es cómo detectarlas antes de que se conviertan en incidente.
Cómo lo detecto cuando evalúo un sistema
En una auditoría yo busco señales de desajuste entre lo que un usuario debería poder hacer y lo que realmente está haciendo. No siempre hay una alarma evidente; a veces el problema se ve en pequeños detalles que, juntos, dibujan una historia bastante clara.
- Cambios inesperados en grupos privilegiados o en pertenencia a roles administrativos.
- Procesos lanzados con contexto de administrador sin una razón operativa clara.
- Binarios con permisos especiales que no tienen una justificación funcional.
- Servicios o tareas programadas escribibles por cuentas que no deberían tocarlos.
- Uso anómalo de herramientas administrativas fuera de horario o desde equipos poco habituales.
- Eventos de UAC, sudo, auditoría del kernel o EDR que no encajan con la actividad normal.
También miro mucho el patrón, no solo el evento. Un intento aislado puede ser ruido; una secuencia de fallos, luego una cuenta que cambia de nivel y después un acceso a secretos sí merece atención. Ahí es donde el análisis de logs, la telemetría del endpoint y la revisión de permisos se complementan bien. Con esa base, la defensa deja de ser reactiva y pasa a ser estructural.
Cómo reduzco el riesgo en Windows, Linux y la nube
Microsoft insiste en el principio de mínimo privilegio, y no es una recomendación decorativa: conceder solo el acceso necesario reduce tanto la superficie de ataque como el impacto de un incidente. Yo lo traduzco así: si una cuenta no necesita una acción, no debería poder ejecutarla, aunque “sea más cómodo” dejarla habilitada.| Entorno | Medidas que más reducen riesgo | Comentario práctico |
|---|---|---|
| Windows | UAC activo, cuentas estándar por defecto, reducción de administradores locales, MFA y control de aplicaciones | UAC ayuda, pero no compensa una política de roles mal hecha |
| Linux | Sudoers mínimo, revisión de setuid/setgid, uso de capabilities, hardening del kernel y separación de cuentas | Menos privilegios especiales significa menos rutas de abuso |
| Cloud y contenedores | IAM de mínimo privilegio, credenciales de corta duración, secretos centralizados y contenedores sin root | Un rol sobredimensionado rompe la contención muy rápido |
En Linux, además, el kernel divide privilegios tradicionales en capacidades más pequeñas, algo útil porque evita dar “todo o nada” cuando solo hace falta una parte concreta. En contenedores, Red Hat recuerda que retirar setuid y setgid en imágenes puede cerrar una vía de escalada muy común; en la práctica, eso suele ser más efectivo que confiar en que “nadie lo va a tocar”.
La parte menos cómoda es que estas medidas introducen fricción operativa. Y, sinceramente, esa fricción es sana si obliga a pedir permisos solo cuando hacen falta. La pregunta siguiente ya no es técnica, sino metodológica: cómo encaja todo esto en un trabajo de hacking ético bien hecho.
Qué aporta al hacking ético y dónde están los límites
En una prueba autorizada, demostrar elevación de privilegios sirve para algo más que “ganar” una máquina. Sirve para medir impacto, validar segmentación, comprobar si el principio de mínimo privilegio está funcionando y priorizar remedios que reduzcan riesgo de forma real. Yo prefiero informes que expliquen el camino completo, desde el acceso inicial hasta el control alcanzado, porque eso le da valor al equipo defensivo.
Ahora bien, hay límites que no conviene cruzar. Si el alcance no lo permite, no tiene sentido insistir en persistencia, extracción de datos o acciones destructivas para “hacer la demo más vistosa”. Lo útil es probar impacto con el menor riesgo posible: evidencias, capturas, logs, validación controlada y una descripción clara de qué habría permitido esa subida de privilegios en un escenario real.
También hay un matiz importante: no todos los hallazgos pesan igual. Una ruta que lleva a administrador local en un equipo aislado no tiene el mismo impacto que una que da acceso a una cuenta de servicio crítica o a un rol cloud con amplio alcance. Yo siempre traduzco el hallazgo a negocio: qué activos toca, qué secretos expone y qué movimiento permite después.
Lo que conviene revisar antes de cerrar una auditoría
Antes de dar una prueba por cerrada, yo reviso cuatro cosas: si existe una ruta clara de cuenta normal a cuenta privilegiada, qué permisos sobran, qué servicios dependen de esos privilegios y qué cambio concreto elimina la vía de abuso. Si esas cuatro preguntas quedan respondidas, el informe suele ser mucho más útil para el equipo que tiene que corregir.
La elevación de privilegios no es solo una técnica de ataque; es un síntoma de que algo en el modelo de acceso está demasiado abierto, demasiado heredado o demasiado confiado. Cuando se corrige bien, el resultado no es solo menos riesgo: también una administración más limpia y predecible.