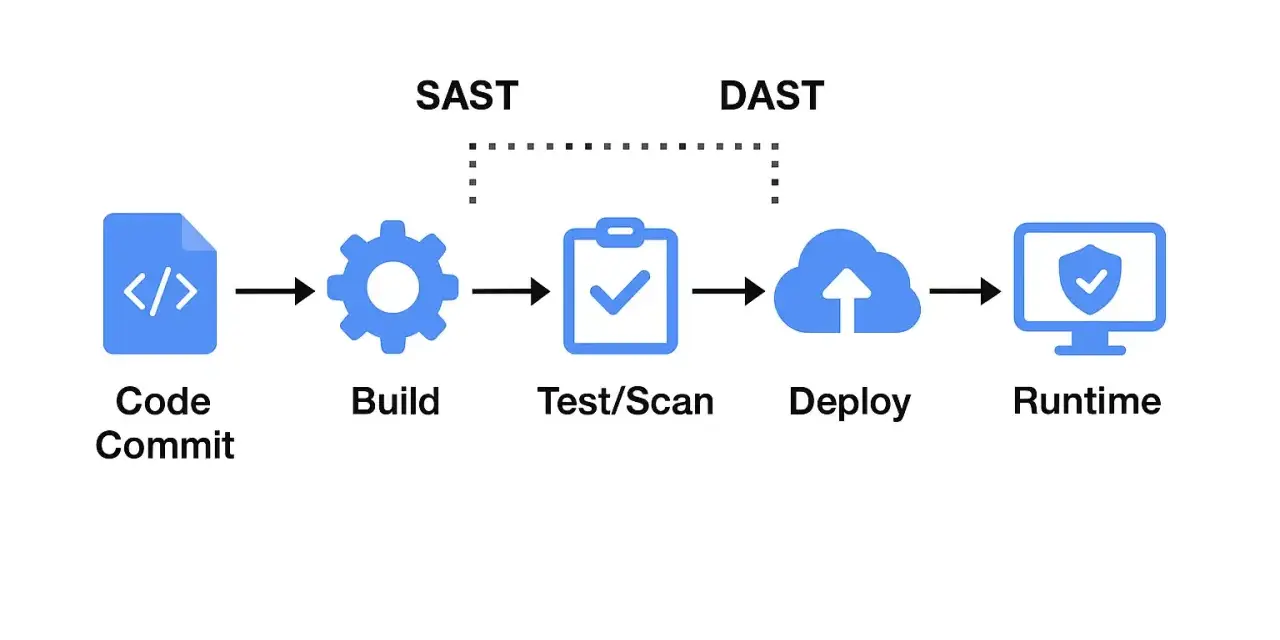
Cuando una aplicación ya está en marcha, la pregunta no es solo si el código parece limpio, sino si aguanta un ataque real, con sesiones, cabeceras, formularios y respuestas del servidor. Ahí entran las dast tools: escáneres y plataformas que prueban la superficie expuesta de una web o API mientras está viva, buscando fallos que un análisis estático no siempre ve. En este artículo explico qué cubren de verdad, qué límites tienen, cómo se comparan las opciones más útiles y qué miraría yo antes de meterlas en un flujo de hacking ético.
Lo esencial de las pruebas dinámicas en aplicaciones reales
- DAST analiza aplicaciones en ejecución desde fuera, sin necesidad de ver el código fuente.
- Detecta especialmente bien inyecciones, XSS, SSRF, misconfiguraciones y ciertos fallos de autenticación.
- No sustituye al pentest manual ni al análisis estático: los complementa.
- Su valor depende de que la herramienta pueda autenticarse, rastrear rutas y validar hallazgos con criterio.
- En hacking ético, el alcance, la autorización y el control de carga no son opcionales.
Qué resuelven realmente las herramientas DAST
Yo las veo como un radar de superficie: observan cómo responde una aplicación cuando le lanzas peticiones maliciosas o extrañas, igual que haría un atacante desde fuera. Esa perspectiva de caja negra es útil porque prueba el sistema tal y como se comporta en producción, no como debería comportarse sobre el papel.
La ventaja práctica es clara. Un equipo puede tener revisiones de código impecables y aun así dejar escapar un endpoint mal protegido, una cabecera mal configurada o un formulario que acepta payloads peligrosos. DAST sirve precisamente para cerrar esa brecha entre el desarrollo y la realidad operativa.
Lo que sí ven
Las DAST suelen brillar cuando el fallo deja rastro en la respuesta del servidor. Ahí entran casos como inyección SQL, XSS reflejado o persistente, errores de autenticación, redirecciones abiertas, SSRF, XXE en algunos escenarios y configuraciones inseguras que se revelan por el comportamiento de la app.
Lo que no ven tan bien
Donde más se atascan es en la lógica de negocio, las condiciones de carrera y ciertos errores que solo aparecen cuando entiendes el flujo completo de la aplicación. OWASP recuerda que estos casos suelen requerir validación manual, y coincido con esa lectura: si el fallo depende de decisiones de negocio o de una secuencia muy concreta de acciones, el escáner puede pasar de largo.
Por eso no me gusta vender DAST como una pieza mágica. Es una capa muy útil, sí, pero su valor real aparece cuando entiendes cómo funciona por dentro el escaneo dinámico.
Cómo funciona un escaneo dinámico de verdad
Un análisis serio no empieza disparando payloads a ciegas. Primero descubre la aplicación, rastrea enlaces, endpoints y formularios, y luego intenta comprender qué partes requieren sesión, qué parámetros cambian la respuesta y qué rutas merece la pena atacar con más intensidad. Ese proceso de crawling es el que marca la diferencia entre encontrar poco y encontrar lo importante.
Después llega la fase de inyección y validación. La herramienta prueba variaciones de entrada y compara respuestas, tiempos, cabeceras, códigos de estado y cambios de contenido. Si detecta una anomalía consistente, la convierte en hallazgo. Si además soporta pruebas fuera de banda, o OAST, puede descubrir vulnerabilidades que no devuelven una señal visible de forma inmediata, algo muy útil en SSRF y en ciertos vectores ciegos.
Autenticación, sesiones y aplicaciones modernas
En aplicaciones con login, tokens rotativos, MFA o SPA pesadas, la calidad del escaneo depende de si la herramienta sabe mantener la sesión y moverse como un usuario real. Si no puede autenticarse bien, el resultado suele ser una foto incompleta. Yo prefiero una DAST algo más lenta pero capaz de entender la navegación real, antes que una muy rápida que apenas recorra la mitad de la app.
APIs y frontends complejos
Hoy ya no basta con revisar formularios HTML clásicos. Muchas superficies de ataque están en APIs REST, GraphQL o backends que responden a llamadas asíncronas desde el navegador. En esos casos, la DAST útil es la que puede adaptarse a esa arquitectura, no la que solo sabe seguir enlaces estáticos.
Con esto claro, ya se entiende mejor por qué unas herramientas encuentran mucho y otras generan ruido. La siguiente pregunta lógica es qué vulnerabilidades detectan bien y cuáles no deberías delegarles.
Qué detectan bien y qué no
Si tuviera que resumirlo en una frase, diría esto: DAST funciona muy bien cuando el fallo se manifiesta en la respuesta de la aplicación, y bastante peor cuando el problema vive en la lógica interna o en una secuencia difícil de reproducir. Esa frontera conviene tenerla muy presente para no exigirle al escáner lo que solo un analista humano puede confirmar.
| Tipo de hallazgo | Resultado típico | Comentario práctico |
|---|---|---|
| SQL injection | Muy bueno | Suele generar señales claras en la respuesta, sobre todo con payloads bien afinados. |
| XSS | Muy bueno | Especialmente útil en entradas reflejadas, formularios y parámetros visibles. |
| SSRF y vectores ciegos | Bueno con OAST | Sin pruebas fuera de banda, muchas veces solo obtienes sospechas, no confirmación. |
| Misconfiguraciones y cabeceras | Bueno | Ayuda a detectar exposición innecesaria, cookies débiles o controles incompletos. |
| Lógica de negocio | Débil | Una herramienta puede ver la ruta, pero no siempre entiende la intención del flujo. |
| Race conditions | Débil | Requiere coordinación, repetición y contexto de negocio. |
| Zero-days | No fiable | No conviene esperar que una firma o un crawler detecte algo que nadie ha modelado aún. |
Mi criterio es sencillo: si una DAST me da una pista, la trato como pista hasta que la valido. Si no lo hago así, me arriesgo a dos errores igual de malos: aceptar un falso positivo o dar por seguro algo que sigue vulnerable.
Por eso la elección de herramienta importa tanto como la categoría técnica. No todas cubren el mismo terreno, y ahí es donde conviene comparar con frialdad.
Cómo elegir la herramienta adecuada
Cuando comparo opciones, no empiezo por el nombre de la marca, sino por el entorno real donde se va a usar. Si el equipo tiene una aplicación sencilla y un presupuesto corto, la prioridad es cobertura razonable y facilidad de automatización. Si hablamos de consultoría, pentesting o AppSec a escala, pesan más la validación manual, la gestión de sesiones, el reporting y la integración con el resto del flujo.
| Opción | Mejor para | Punto fuerte | Límite |
|---|---|---|---|
| OWASP ZAP | Equipos pequeños, laboratorios y pipelines básicos | Es gratis, flexible y muy útil para automatizar pruebas iniciales | Requiere ajuste fino y puede generar más ruido si se usa sin criterio |
| Burp Suite DAST | Pentesters y equipos que mezclan automatización con revisión manual | Tiene un ecosistema muy sólido para probar, validar y profundizar | La curva de aprendizaje y la licencia pesan más que en una opción abierta |
| Plataformas enterprise | Organizaciones con muchas apps, reporting y gobernanza centralizada | Escalan mejor, integran políticas y suelen encajar bien en DevSecOps | Más coste y más trabajo de configuración inicial |
Yo priorizaría cinco cosas antes de decidir: autenticación persistente, soporte para APIs, capacidad de integrar en CI/CD, calidad del reporting y control de falsos positivos. Si la herramienta falla en uno de esos puntos críticos para tu caso, por muy conocida que sea, no es la adecuada para ti.
En un entorno de hacking ético en España, además, me fijaría en otra cuestión muy básica: que la herramienta permita limitar el alcance con precisión y documentar bien qué se ha probado. Eso evita problemas técnicos y también operativos cuando trabajas con entornos que contienen datos reales.Elegir bien, sin embargo, solo resuelve la mitad del problema. La otra mitad es integrarla sin romper nada.
Cómo encajarla en un flujo de hacking ético y DevSecOps
La regla que mejor me funciona es simple: primero autorización, luego alcance y después ruido mínimo. En un proceso serio, la DAST no se lanza contra producción sin control, sino contra un entorno acordado, con credenciales de prueba, ventanas de ejecución y límites claros de carga. Eso no es burocracia; es lo que convierte una prueba técnica en una prueba profesional.
Antes del escaneo
- Define el alcance exacto: dominios, subdominios, rutas, APIs y exclusiones.
- Usa credenciales de prueba y confirma que siguen activas durante toda la prueba.
- Configura rate limiting para no saturar servicios sensibles ni disparar bloqueos innecesarios.
- Decide si el objetivo es staging, preproducción o producción y documenta la diferencia.
Durante la ejecución
- Empieza con un escaneo conservador y sube intensidad solo si el entorno lo soporta.
- Monitorea latencia, errores 5xx y comportamiento anómalo del backend.
- Usa OAST cuando busques vectores ciegos o confirmación externa.
- No fuerces bruteforce ni payloads agresivos si no están expresamente permitidos.
Lee también: Tipos de hackers: ¿Quién es ético y quién no? Descúbrelo
Después del hallazgo
- Valida manualmente los resultados que puedan afectar a la decisión de remediación.
- Elimina duplicados y prioriza por impacto real, no por color en el panel.
- Repite la prueba tras corregir la vulnerabilidad para confirmar que no reaparece.
- Deja evidencia clara para desarrollo, seguridad y auditoría interna.
Cuando este circuito está bien montado, la DAST se convierte en una pieza muy útil de DevSecOps: aporta cobertura continua, detecta regresiones y reduce tiempo perdido en revisión manual de problemas obvios. El siguiente escollo, paradójicamente, aparece cuando el equipo confía demasiado en el informe automático.
Los errores que veo una y otra vez
Hay patrones que se repiten tanto que casi podrían ser una lista de control de lo que no hay que hacer. El primero es escanear sin autenticación real y luego sacar conclusiones sobre toda la aplicación. El segundo, tratar el score como si fuera una verdad absoluta. El tercero, ignorar que una web moderna puede necesitar navegador real, scripts y persistencia de sesión para revelar su superficie de ataque de verdad.
- Escaneo sin login: deja fuera la parte más sensible de muchas aplicaciones.
- Configuración por defecto: útil para empezar, insuficiente para una prueba seria.
- Confundir ruido con valor: más hallazgos no significa mejor seguridad.
- No validar manualmente: el informe ayuda, pero no cierra el caso.
- No reescANear tras la corrección: arreglar sin verificar es dejar la historia a medias.
Yo suelo insistir mucho en esto: una DAST no reemplaza el criterio. Lo acelera, lo escala y lo hace más consistente, pero no decide por ti qué importa de verdad. Si el equipo no sabe leer el resultado, la herramienta solo amplifica la confusión.
Y eso me lleva a la última decisión importante: qué revisar antes de desplegarla o comprarla para evitar precisamente esa confusión.
Lo que separa una DAST útil de un generador de ruido
Si tuviera que elegir solo una idea para cerrar, sería esta: una DAST útil no es la que más vulnerabilidades “encuentra”, sino la que encuentra las correctas con el menor coste operativo posible. En 2026, la diferencia real ya no está en escanear por escanear, sino en integrar mejor, validar mejor y molestar menos al entorno.
- ¿Se autentica de forma fiable en tu aplicación real?
- ¿Entiende bien APIs, frontends modernos y flujos con tokens?
- ¿Permite limitar alcance, intensidad y ventanas de ejecución?
- ¿Te da informes accionables o solo una lista larga de alertas?
- ¿Encaja con tu forma de trabajar: pentest, DevSecOps o monitorización continua?
Mi recomendación práctica es empezar pequeño y medir bien. Para un equipo que quiere aprender y cubrir lo básico, una opción abierta bien configurada puede ser suficiente. Si el trabajo exige validación profunda y menos fricción en el análisis manual, una suite más completa compensa. Y si la organización necesita escala, gobierno y trazabilidad, entonces merece la pena mirar plataformas enterprise con cuidado, no por inercia. En hacking ético, la buena herramienta no es la más ruidosa, sino la que te permite probar mejor sin perder control.