
Una prueba de xss test bien planteada no consiste en lanzar cadenas raras al azar; consiste en entender cómo trata la aplicación la entrada del usuario, en qué contexto la devuelve y si el navegador la interpreta como código. En una auditoría ética, esa diferencia cambia por completo el resultado: lo que parece un simple texto puede convertirse en una ejecución en el navegador si el flujo está mal protegido. Aquí explico cómo enfoco una revisión útil, qué variantes conviene separar, qué señales busco y qué hago cuando encuentro un hallazgo real.
Lo que necesitas tener claro antes de probar XSS
- El riesgo aparece en la salida, no solo en la entrada: importa dónde se renderiza el dato y cómo se escapa.
- Hay cuatro familias que conviene distinguir: reflejado, almacenado, DOM y blind XSS.
- La prueba útil empieza por el contexto: HTML, atributos, JavaScript, URLs y sinks del lado del cliente.
- Las herramientas aceleran, pero el navegador y la validación manual siguen siendo decisivos.
- Un hallazgo serio debe ser reproducible, comprensible y corregible sin efectos secundarios.
Qué abarca realmente una prueba de XSS y por qué importa
OWASP suele separar el problema en reflejado, almacenado y DOM; yo añado el caso blind cuando audito flujos asíncronos, paneles internos o procesos que no muestran el resultado en el mismo momento. PortSwigger insiste en algo con lo que coincido: en XSS manda el contexto, porque no se prueba igual una respuesta HTML que una cadena que acaba dentro de JavaScript. Esa distinción evita dos errores clásicos: pensar que todo XSS se comporta igual y dar por segura una ruta solo porque el navegador no ejecutó nada en el primer intento.
| Tipo | Dónde aparece | Cómo se suele detectar | Riesgo típico |
|---|---|---|---|
| Reflejado | La entrada vuelve en la respuesta inmediata | Parámetros, búsquedas, filtros, mensajes de error | Afecta a quien abre una URL o interacción maliciosa |
| Almacenado | La entrada se guarda y reaparece después | Comentarios, perfiles, tickets, foros, CMS | Más impacto porque puede alcanzar a más usuarios |
| DOM | La manipulación ocurre en el navegador | JavaScript que lee fuentes inseguras y escribe en sinks | Difícil de ver si solo miras la respuesta del servidor |
| Blind | La ejecución no se ve en la pantalla revisada | Paneles internos, tareas diferidas, procesado asíncrono | La validación tarda más y requiere más trazabilidad |
Cuando separo estas variantes desde el inicio, la prueba gana precisión y pierdo menos tiempo persiguiendo falsos indicios. Esa base me lleva al siguiente paso: ordenar el trabajo para que la revisión sea repetible y no una sucesión de intentos improvisados.
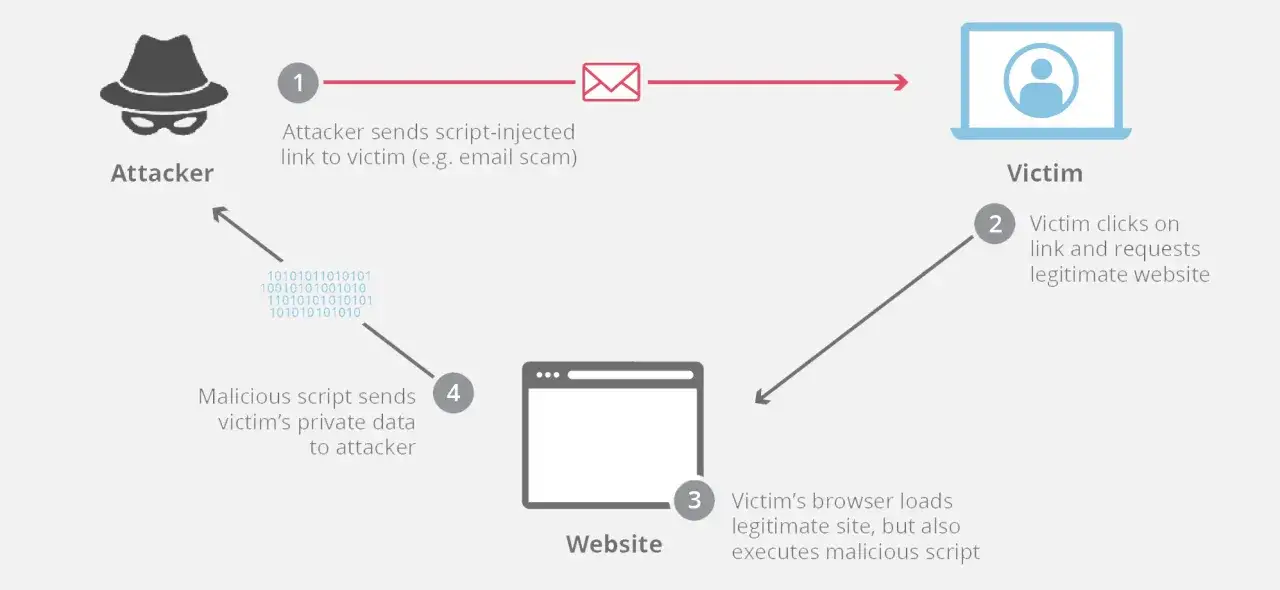
Cómo planteo un xss test autorizado paso a paso
Yo no empiezo por payloads complejos. Empiezo por el mapa: qué campos acepta la aplicación, dónde reaparecen esos datos y qué controles de escape ya existen. Si no hay autorización explícita para probar el entorno, no se continúa; en hacking ético, el alcance define tanto la utilidad de la prueba como su seguridad operacional.
- Inventario las superficies de entrada: formularios, parámetros de URL, cabeceras, archivos, perfiles, APIs y flujos internos.
- Localizo la salida: identifico en qué página, componente o respuesta reaparece el dato y bajo qué condición.
- Pruebo con marcadores inocuos: busco si el contenido llega escapado, truncado, codificado o transformado por una librería.
- Repito en varios estados: sesión iniciada y cerrada, distintos roles, navegador limpio, caché vacía y rutas alternativas.
- Compruebo si la evidencia es estable: un hallazgo real debe poder reproducirse sin depender de coincidencias raras.
- Documentó el contexto exacto: no basta con decir “hay XSS”; hay que explicar dónde entra, dónde sale y por qué se ejecuta.
Para apoyarme, uso navegador con herramientas de desarrollo, un proxy de interceptación y, cuando merece la pena, un escáner que me ayude a cubrir rutas repetitivas. Aun así, la automatización solo acelera una parte del trabajo: la decisión de si hay vulnerabilidad o no sigue dependiendo de cómo se comporta la aplicación en cada contexto. Con eso claro, la clave pasa a ser leer correctamente la salida.
Los contextos de salida que más suelo comprobar primero
No todos los sitios fallan en el mismo punto. Una aplicación puede escapar correctamente el texto plano y, sin embargo, fallar en un atributo HTML, en una cadena JavaScript o en un componente del front que reutiliza datos sin sanitizar. Yo suelo revisar primero estos contextos porque ahí se concentran muchos errores reales.
| Contexto | Qué observo | Señal de alerta | Qué suele necesitar |
|---|---|---|---|
| Cuerpo HTML | Si el texto se inserta como contenido o como marcado | Aparecen etiquetas o fragmentos no escapados | Codificación de salida específica para HTML |
| Atributo HTML | Si el dato cae dentro de una propiedad como `value`, `title` o `data-*` | Comillas, espacios o separadores rompen la estructura | Escape de atributos y validación de formato |
| JavaScript | Si el dato termina dentro de una cadena, objeto o variable | La aplicación mezcla datos y código en la misma lógica | Codificación para contexto JS o rediseño del flujo |
| URL y redirecciones | Si el valor viaja por parámetros o enlaces generados | Parámetros reinyectados sin control | Validación estricta y listas permitidas |
| Sink del DOM | Si un script escribe datos en puntos sensibles del navegador | Uso inseguro de `innerHTML`, `document.write` u operaciones equivalentes | Reemplazar el sink o sanear antes de escribir |
Un “sink” es el punto donde el navegador consume el dato. Si ese punto interpreta entrada no confiable como marcado o código, el problema puede existir aunque el servidor parezca correcto. Esta es la razón por la que muchas pruebas se quedan cortas cuando solo miran la respuesta HTTP y no el comportamiento real del cliente. Entender el contexto me permite distinguir una vulnerabilidad de una simple salida escapada, y eso me lleva a los errores que más confunden a principiantes y a equipos con prisa.
Errores que hacen que una prueba parezca válida cuando no lo es
La mayoría de los fallos de criterio no vienen por falta de herramientas, sino por interpretar mal lo que se ve. En una revisión seria, yo vigilo sobre todo estos puntos:
- Confundir escape con sanitización: escapar la salida no es lo mismo que limpiar la entrada, y cada caso tiene implicaciones distintas.
- Dar por cerrado un caso porque el navegador no ejecutó nada: muchas veces el problema está en otro contexto o en otra ruta.
- Mirar solo el primer reflejo: en XSS almacenado o de segunda orden, el impacto aparece más tarde y en otra vista.
- Confiar demasiado en un WAF: un filtro puede bloquear un intento puntual y dejar abierto el diseño vulnerable.
- Probar un único navegador: algunos errores dependen de diferencias en la interpretación del DOM o en librerías concretas.
- No comprobar el después del arreglo: una corrección parcial suele dejar rutas secundarias sin cubrir.
También conviene evitar una trampa muy común: si el texto aparece solo como texto escapado, no hay evidencia de XSS, hay evidencia de una defensa funcionando. Esa diferencia parece obvia sobre el papel, pero en auditorías reales ahorra discusiones y reportes mal redactados. Cuando la prueba está bien hecha, el siguiente paso es aún más importante: convertir el hallazgo en una corrección durable.
Cómo cierro un hallazgo de XSS para que no vuelva a aparecer
Cuando confirmo una vulnerabilidad, no me quedo en “hay problema”. Lo útil es dejar claro qué capa falló y qué debe cambiar para que el parche no sea cosmético. En mi experiencia, las correcciones que mejor aguantan el tiempo combinan tres ideas: salida codificada según contexto, uso prudente de sanitización y defensa en profundidad.
- Codificación contextual de salida: el HTML, los atributos y el JavaScript no se tratan igual.
- Sanitización solo donde aporta valor real: si el sitio permite contenido enriquecido, hay que definir qué etiquetas y atributos se aceptan.
- Políticas CSP bien pensadas: una Content Security Policy ayuda, pero no sustituye el saneamiento correcto.
- Revisión de plantillas y componentes: un cambio en el front puede reabrir una ruta ya corregida.
- Pruebas de regresión: el mismo caso que falló debe quedar automatizado o, al menos, documentado para repetirlo tras cada despliegue.
Si algo me parece especialmente útil para equipos pequeños es esto: un buen cierre de XSS no termina en el bug, termina en una regla de desarrollo que evita que el mismo patrón reaparezca en otra pantalla. Esa es la diferencia entre apagar un incendio puntual y mejorar de verdad la postura de seguridad de la aplicación.