El arp poisoning sigue siendo una de las técnicas más útiles para entender cómo se rompe la confianza dentro de una red local. En este artículo explico cómo funciona el ataque a nivel de ARP, qué efecto tiene sobre la caché de los equipos, qué señales lo delatan y qué medidas sí marcan diferencia en una auditoría de hacking ético. Mi objetivo es que salgas con una visión técnica pero práctica, no con una definición vacía.
Lo esencial para entender este ataque en minutos
- ARP resuelve direcciones IPv4 a direcciones MAC dentro de la misma red local, pero no autentica quién responde.
- El ataque busca que víctima y puerta de enlace aprendan una MAC falsa y redirijan el tráfico hacia un tercero.
- El impacto más común es un ataque intermediario, aunque también puede terminar en robo de datos o en denegación de servicio.
- Las defensas más sólidas combinan inspección dinámica de ARP, snooping DHCP, segmentación y monitorización de cambios IP/MAC.
- Las protecciones solo en el equipo final suelen ser insuficientes si el problema real está en el acceso de red.
Qué papel juega ARP en una red IPv4
ARP existe para responder una pregunta simple: “si ya sé la IP de destino, ¿qué MAC uso para entregar la trama en la red local?”. Ese mecanismo es práctico, pero nació para resolver direcciones, no para validar identidades. Por eso una máquina acepta una respuesta ARP si le encaja con lo que espera en ese momento, aunque no exista una autenticación criptográfica detrás.
En la práctica, eso crea una caché local con pares IP/MAC que se actualiza dinámicamente. Si un equipo aprende una asociación falsa, puede empezar a enviar tráfico al lugar equivocado durante un tiempo, hasta que la tabla se corrija o caduque. Ese detalle, que parece menor, es exactamente el punto débil que explota el envenenamiento de ARP.
Conviene aclarar un matiz: en IPv6 el problema equivalente ya no se llama ARP, sino Neighbor Discovery. Es otro protocolo y otro conjunto de riesgos, así que aquí me centro en redes IPv4, donde este vector sigue teniendo mucho sentido operativo. Con esa base clara, ya se entiende por qué el siguiente paso del ataque es engañar a la caché.
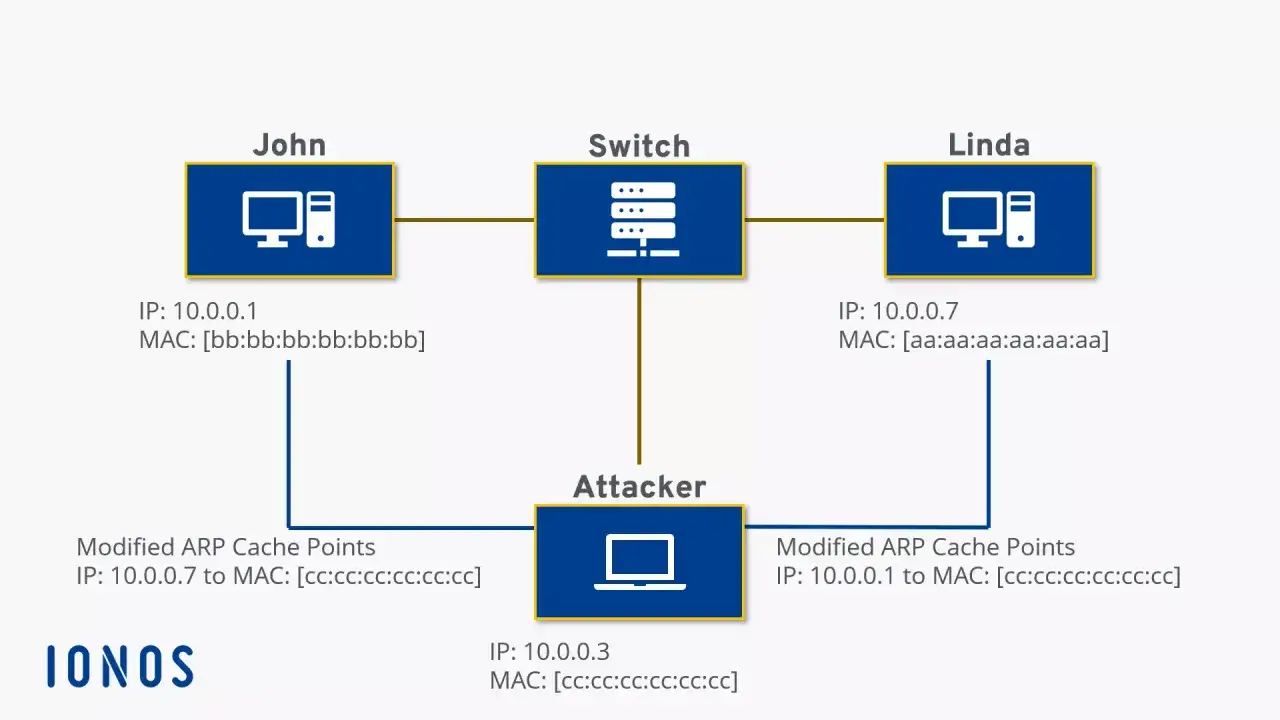
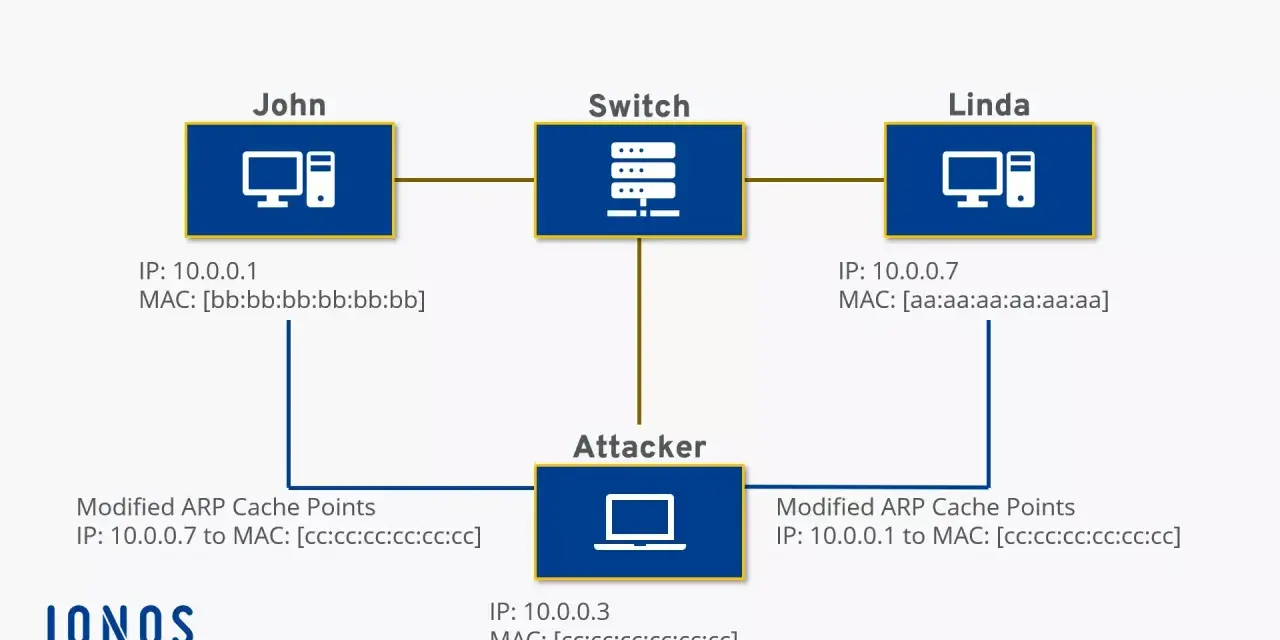
Cómo se altera la caché para desviar el tráfico
La técnica suele apoyarse en respuestas ARP falsificadas o en anuncios ARP gratuitos que hacen creer a la víctima que una IP legítima, normalmente la puerta de enlace, corresponde a la MAC del atacante. Si ese mismo engaño se repite en sentido inverso, el atacante también consigue que la puerta de enlace asocie la IP de la víctima con su propia MAC. En ese momento, las dos partes empiezan a enviarle tráfico a él.
Yo suelo resumir el mecanismo en tres fases:
- El atacante está dentro del mismo dominio de difusión o del mismo segmento lógico que la víctima.
- Envía información ARP falsa para que los equipos actualicen su caché con una asociación errónea.
- El tráfico pasa a través de su equipo, que puede reenviarlo, modificarlo o simplemente dejarlo caer.
En redes bien administradas, esta fase puede fallar por inspección de ARP, por bindings DHCP o por ACLs de ARP en equipos con IP estática. Eso nos lleva a la pregunta importante: qué gana realmente el atacante cuando el engaño sí prospera.
Qué consigue un atacante y por qué el daño no siempre es igual
El resultado más típico es un ataque intermediario. Si el tráfico no va cifrado, el atacante puede leer credenciales, cookies, consultas DNS o contenido de aplicaciones antiguas que aún viajan en claro. Si hay TLS bien implementado, la situación cambia: el contenido se protege, pero el atacante sigue viendo metadatos útiles, como destinos, volumen de tráfico y patrones de conexión.
También puede optar por un escenario de interrupción. Si el equipo que ha envenenado las tablas no reenvía correctamente el tráfico, la víctima pierde conectividad o sufre cortes intermitentes difíciles de diagnosticar. En auditorías reales, este detalle es importante: no todo ARP malicioso busca espionaje; a veces el objetivo es degradar el servicio o provocar caos en un segmento concreto.
- Intercepción: útil cuando el tráfico viaja sin cifrar o cuando el atacante busca información lateral.
- Manipulación: más difícil en sistemas modernos, pero posible en flujos poco protegidos.
- Denegación de servicio: suficiente con bloquear el reenvío o saturar la red local.
- Alcance limitado: funciona dentro del mismo segmento L2, así que no es una amenaza universal para toda la empresa.
Mi lectura práctica es esta: cuanto más plana y más confiada sea la red, más valor tiene este vector. Cuanto más segmentada, más visible y más controlada esté la capa de acceso, menos rentable resulta. Por eso el siguiente paso no es solo bloquear, sino detectar a tiempo.
Cómo detectarlo antes de que el problema escale
Cuando reviso una red, busco señales que no encajan con el comportamiento normal. La más obvia es un cambio repetido de la MAC asociada a la puerta de enlace o a servidores críticos. Otra muy útil es ver varios cambios de IP/MAC en poco tiempo, especialmente si afectan a equipos que no deberían moverse de forma frecuente. Eso no siempre significa ataque, porque hay failover, virtualización y balanceadores, pero sí merece verificación inmediata.
Herramientas como arpwatch ayudan justo en ese punto: registran pares Ethernet/IP y avisan cuando cambian. En un entorno bien vigilado, esos avisos son oro, porque transforman una sospecha difusa en un evento concreto que puedes correlacionar con logs del switch, capturas de tráfico o incidencias reportadas por usuarios.
| Señal o herramienta | Qué aporta | Limitación práctica |
|---|---|---|
| Cambios repetidos de la MAC del gateway | Indica que una IP crítica está resolviendo hacia destinos distintos | Puede confundirse con un failover legítimo si no conoces la topología |
| arpwatch | Detecta cambios de pares IP/MAC y los registra | Necesita visibilidad sobre el segmento que quieres vigilar |
| Logs de inspección dinámica de ARP | Dejan rastro cuando se descartan paquetes inválidos | Solo sirve si la función está activa y bien configurada |
| Captura de tráfico | Permite ver respuestas ARP incoherentes o repetitivas | Es más manual y consume tiempo en entornos grandes |
Si un monitor muestra cambios pero no puedes confirmar si son legítimos, yo no cierro el caso todavía. Cruzo eventos, reviso el puerto de acceso y miro si el comportamiento coincide con un movimiento real de infraestructura o con un intento de suplantación. Esa correlación marca la diferencia entre una falsa alarma y un incidente real, y abre la puerta a la parte más importante: las defensas que de verdad aguantan.
Qué controles sí reducen el riesgo de forma realista
La defensa eficaz contra este ataque no depende de un único producto, sino de varias capas que se apoyan entre sí. Si me obligan a priorizar, empiezo por el plano de acceso, no por el puesto del usuario. Ahí es donde se puede validar si una IP pertenece de verdad a una MAC concreta y si el tráfico ARP tiene sentido.
| Control | Cuándo me interesa | Qué limita |
|---|---|---|
| Inspección dinámica de ARP | En switches gestionados con usuarios finales y VLANs bien definidas | Bloquea respuestas incoherentes, pero necesita una base de bindings fiable |
| Snooping DHCP | Cuando la mayoría de equipos obtiene dirección automáticamente | Construye la tabla de confianza que otras funciones usan para validar ARP |
| ACLs de ARP para IP estática | En servidores, impresoras o equipos que no usan DHCP | Reduce el trabajo manual, pero exige mantener excepciones actualizadas |
| Segmentación y puertos de confianza mínimos | Cuando quiero acotar el radio de acción de un atacante interno | No evita el problema si confío demasiado en enlaces que no debería |
| Cifrado extremo a extremo | Siempre, porque protege el contenido aunque la red falle | No impide la suplantación ARP, solo reduce el valor del tráfico interceptado |
En algunos switches, el límite por defecto en puertos no confiables ronda los 15 paquetes por segundo, una medida pensada para frenar abusos y evitar que el propio control se convierta en carga. Aun así, ese tipo de cifra no sustituye la configuración correcta: si el puerto está mal marcado como confiable, o si los bindings no existen, el control pierde sentido. Mi criterio es simple: primero valido la fuente de verdad, luego el filtrado.
Para redes con equipos de IP fija, no me basta con confiar en DHCP. Ahí ajusto listas de control, reviso excepciones y compruebo que el switch realmente conoce qué MAC pertenece a cada dirección crítica. Esa parte es menos vistosa que un gran firewall, pero en la práctica suele ser la que evita el incidente.
Errores que yo veo una y otra vez en auditorías
Hay patrones que se repiten demasiado. El primero es activar controles en un tramo de la red y dar por hecho que todo el VLAN queda cubierto. El segundo es confiar enlaces entre switches que en realidad transportan tráfico de usuario y no deberían estar exentos de validación. El tercero es olvidar por completo los hosts con IP estática, justo donde la automatización deja de ayudarte.
- Dar por buena la configuración por defecto cuando la protección depende de una validación que todavía no existe.
- Confiar puertos de acceso sin necesidad, lo que abre una vía de bypass muy difícil de justificar.
- No inventariar las direcciones estáticas, dejando huecos donde el control no sabe qué validar.
- Depender solo del endpoint, como si un antivirus en el puesto pudiera arreglar una debilidad de capa 2.
- No revisar falsos positivos, especialmente en entornos con virtualización, balanceo o sustitución de gateways.
Lo que revisaría antes de dar la red por cerrada
Si cierro una auditoría de capa 2, lo primero que verifico es si la red sabe quién puede hablar con quién y con qué dirección MAC. Lo segundo es si los eventos anómalos quedan registrados con suficiente detalle para reconstruir lo ocurrido. Y lo tercero es si los segmentos críticos están de verdad aislados del ruido de usuario, no solo en el diagrama bonito del proyecto.
Mi conclusión práctica es bastante directa: el envenenamiento ARP no es un ataque sofisticado, pero sí es una prueba muy eficaz de madurez de red. Si la infraestructura está bien segmentada, si la validación de bindings está activa y si los cambios IP/MAC se monitorizan, el ataque deja de ser una sorpresa y pasa a ser un evento visible, acotado y tratable. Si falla alguna de esas piezas, el problema no es solo el atacante; es el diseño que le dejó el camino abierto.