
La inyección SQL sigue siendo una de las fallas más delicadas en aplicaciones web porque convierte un formulario, una URL o una API en una vía para alterar consultas de base de datos. En este artículo explico cómo funciona, dónde suele aparecer, qué variantes conviene distinguir en una auditoría ética y qué medidas la frenan de verdad, sin quedarme en teoría.
La parte importante no es solo detectar que existe una vulnerabilidad: también hay que entender su impacto real, porque puede ir desde la lectura de datos hasta la modificación de registros, el salto de lógica de negocio o la exposición de información sensible. Si trabajas en desarrollo, revisión de código o hacking ético, este es uno de esos temas que conviene dominar con precisión.
Lo más importante que conviene tener claro antes de entrar en detalle
- La falla aparece cuando la aplicación mezcla datos del usuario con instrucciones SQL sin separar ambos planos.
- El daño no se limita a “leer una tabla”: también puede alterar datos, saltarse controles y dejar rastros difíciles de ver.
- Las variantes ciegas y de segundo orden son especialmente traicioneras porque no siempre muestran errores obvios.
- La defensa más sólida sigue siendo la misma: consultas parametrizadas, validación por lista permitida y privilegios mínimos.
- En hacking ético, lo correcto es probar con método, documentar evidencias y reproducir el hallazgo en un entorno controlado.
Qué es realmente la inyección SQL
La inyección SQL ocurre cuando una aplicación construye una consulta con datos no confiables y termina tratando esos datos como si fueran parte de la lógica de la base de datos. Dicho de forma simple: lo que debía ser contenido acaba influyendo en la instrucción. Ahí está el problema.
Yo suelo explicarlo así: una consulta debe tener una frontera clara entre datos e instrucciones. Cuando esa frontera se rompe por concatenación, interpolación o construcción dinámica mal controlada, el atacante puede interferir en la consulta, forzar resultados distintos o acceder a información que no debería ver.
El impacto depende del contexto, pero no suele quedarse en una simple anomalía. Puede afectar autenticación, filtros de búsqueda, paneles de administración, exportaciones, informes y cualquier función que arme SQL a partir de entrada externa. Con esa base clara, merece la pena mirar dónde aparece en la práctica.
Dónde aparece en una aplicación real
En auditorías, casi siempre encuentro patrones repetidos. El error no suele ser “la base de datos es insegura”, sino una consulta mal construida en un punto concreto del flujo. Esta tabla resume los casos que más reviso.
| Patrón habitual | Qué suele fallar | Señal de alerta |
|---|---|---|
| Login o búsqueda con concatenación directa | El valor de entrada acaba dentro del WHERE como texto SQL | La consulta cambia según el contenido del campo y no según parámetros seguros |
| Filtros por ordenación o paginación | Se aceptan nombres de columna o dirección de orden sin lista permitida | El sistema deja elegir libremente columnas, tablas o expresiones |
| Datos JSON o XML convertidos en consulta | La capa intermedia “normaliza” la entrada, pero la pasa sin parametrizar | La vulnerabilidad no está en el formulario clásico, sino en una API |
| Procedimientos almacenados con SQL dinámico | Se confunde “usar un stored procedure” con “estar protegido” | Dentro del procedimiento hay concatenación o ejecución dinámica |
El matiz importante es este: muchas veces la vulnerabilidad no está en el sitio más obvio. Puede estar en una búsqueda, en un filtro interno, en una exportación CSV o en una llamada de backend que nadie revisa porque “no la toca el usuario”. Y eso me lleva a distinguir las variantes que conviene separar en una auditoría.
Las variantes que conviene distinguir en una auditoría
Como hace PortSwigger en su guía técnica, yo separo la SQLi en cuatro formas que de verdad importan durante una revisión. No todas se comportan igual, y confundirlas hace perder tiempo.
| Variante | Cómo se presenta | Por qué importa |
|---|---|---|
| En banda | La respuesta devuelve directamente parte de los datos consultados | Suele ser la más fácil de detectar y también la más peligrosa si se ignora |
| Ciega | No hay datos visibles, pero cambian las respuestas o los tiempos | Pasa desapercibida con pruebas superficiales y puede seguir explotándose |
| Fuera de banda | La evidencia llega por otro canal, no por la respuesta normal de la app | Es útil cuando la aplicación oculta errores o bloquea señales directas |
| De segundo orden | La entrada se guarda primero y se reutiliza después en una consulta insegura | Es especialmente traicionera porque el fallo aparece más tarde y en otro flujo |
La conclusión práctica es simple: si solo buscas errores visibles en pantalla, te vas a dejar fuera una parte importante del problema. Por eso, cuando la quiero detectar de forma ética, trabajo con un método más amplio y no con una sola prueba aislada.
Cómo la detecto sin salir del marco ético
La detección responsable empieza antes de tocar herramientas. Primero reviso dónde entra el dato, cómo viaja por la aplicación y en qué punto llega a la consulta. Después verifico si la entrada se parametriza, si hay validaciones por lista permitida y si el comportamiento cambia entre valores normales y valores con formato extraño.
- Localizo todos los puntos de entrada: formularios, filtros, parámetros de URL, cabeceras, JSON y tareas de backend.
- Reviso el código o la traza de ejecución para ver si la consulta se construye con parámetros seguros o con concatenación.
- Compruebo si hay diferencias consistentes en respuesta, validación o tiempos cuando varío la entrada de forma controlada.
- Busco señales de vulnerabilidad ciega, como cambios lógicos sin mensaje de error aparente o latencias anómalas.
- Registro evidencias reproducibles en un entorno de pruebas, no en producción.
- Contrasto el hallazgo con logs, observabilidad y comportamiento del motor de base de datos cuando el acceso lo permite.
Cuando trabajo con herramientas, prefiero un proxy de pruebas y un escáner bien configurado antes que lanzar automatización sin criterio. La automatización ayuda, pero no sustituye la lectura de la aplicación ni la revisión de la lógica. Y, una vez detectado el problema, la pregunta correcta ya no es “¿cómo lo exploto más?”, sino “¿qué lo bloquea de verdad?”.
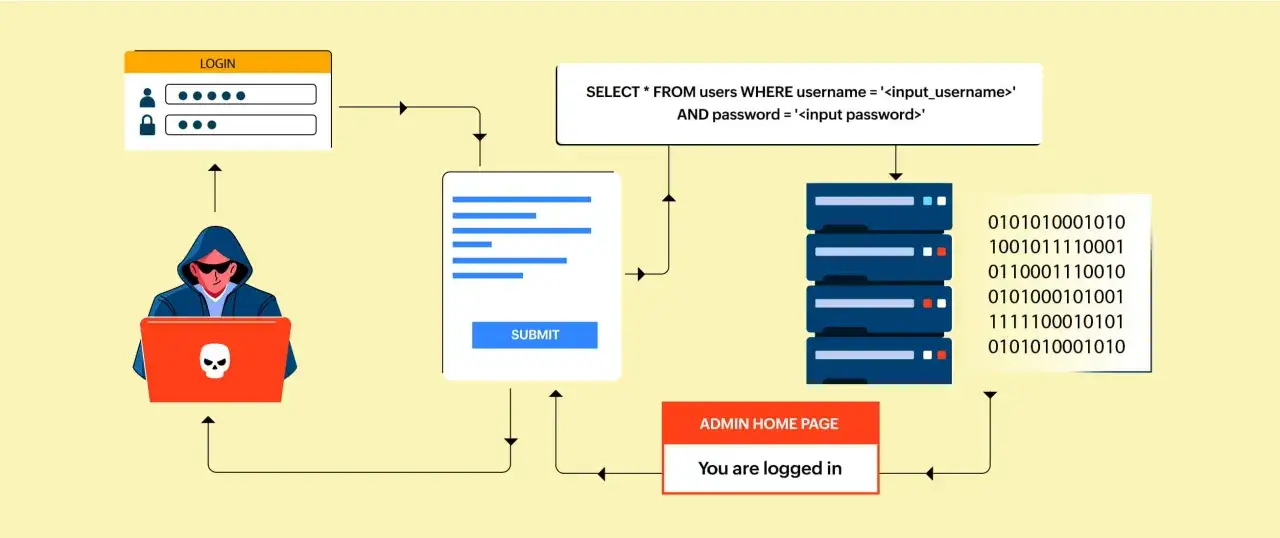
Qué la bloquea de verdad en el código
Si tuviera que elegir una sola defensa, elegiría consultas parametrizadas. OWASP la recomienda como la base porque separa los datos de la instrucción SQL y evita que el valor de entrada cambie la estructura de la consulta. Todo lo demás funciona mejor cuando esa base está bien puesta.
| Medida | Cómo ayuda | Límite real |
|---|---|---|
| Consultas parametrizadas | Separan datos e instrucciones y neutralizan la concatenación insegura | No resuelven por sí solas los casos en que se inyectan nombres de columna o tabla |
| Validación por lista permitida | Restringe valores como columnas, estados o direcciones de ordenación | Debe combinarse con parametrización; no es un sustituto |
| Procedimientos almacenados bien diseñados | Encapsulan lógica y pueden reducir superficie de ataque | Si construyen SQL dinámico por dentro, siguen siendo vulnerables |
| Privilegio mínimo | Reduce el impacto si una consulta se compromete | No impide la inyección, solo limita el daño |
| Manejo prudente de errores | Evita que el motor filtre información útil al atacante | No corrige la causa raíz |
| WAF o capa de filtrado | Añade fricción y detecta patrones conocidos | No debe tratarse como defensa principal |
Mi opinión es clara: el escapado manual solo me parece aceptable como última línea, nunca como estrategia principal. Es fácil aplicarlo mal, depende del motor y tiende a romperse cuando el código crece. La defensa buena no intenta “limpiar” una cadena peligrosa; evita que la cadena llegue a convertirse en instrucción.
Errores que siguen dejando la puerta abierta
Hay fallos que veo una y otra vez, incluso en equipos con experiencia.
- Validar solo en el frontend y asumir que el backend recibirá siempre datos limpios.
- Confiar ciegamente en un ORM sin revisar consultas nativas o fragmentos dinámicos.
- Usar parámetros seguros en unas partes y concatenación en otras, sobre todo en ordenación, filtros o búsquedas avanzadas.
- Tratar datos almacenados como si fueran automáticamente confiables, lo que abre la puerta a una SQLi de segundo orden.
- Exponer mensajes de error del motor de base de datos en producción.
- Creer que un WAF compensa una arquitectura mal diseñada.
Estos errores no solo aumentan el riesgo técnico; también complican la revisión posterior porque mezclan síntomas, falsos positivos y rutas de entrada distintas. Por eso, cuando ya localizo el fallo, no me limito a “parchear” una consulta y seguir. Cierro la auditoría de otra manera.
Lo que conviene dejar atado antes de cerrar una auditoría
Cuando un hallazgo de SQLi se corrige bien, no basta con cambiar una línea y marcar la tarea como resuelta. Yo suelo comprobar tres cosas: que la consulta ya no concatena entrada no confiable, que el comportamiento ha quedado cubierto por pruebas de regresión y que el modelo de permisos del usuario de base de datos es realmente mínimo.También reviso que el equipo haya convertido la corrección en una práctica reutilizable. Si el patrón se repite en otras funciones, la solución debe llegar a todo el código relacionado, no solo al punto que falló primero. Ahí es donde una vulnerabilidad deja de ser un incidente aislado y se convierte en una mejora estructural.
Si tengo que resumir la prioridad técnica, diría esto: separa datos e instrucciones, limita privilegios, prueba los flujos críticos y no te fíes de que una sola herramienta te avise de todo. Cuando esa disciplina está bien integrada, la inyección SQL deja de ser un susto recurrente y pasa a ser un problema bien controlado.